Insurance companies receive numerous emails, which contain requests for proposal (RFP) quotes from brokers. These emails have valuable information that can help insurers to make informed decisions about coverage and pricing. However, extracting data with the desired accuracy from emails can be a significant challenge even with the help of AI. Here are some of the challenges while using AI to extract data from RFP quotes.
- Unstructured data: Email data lacks a predefined structure and contains information in a variety of formats such as blobs of text, images, and attachments. AI must consider data present in the subject, email body, signature as well as attachments. AI models must be able to extract and integrate relevant data from these sources.
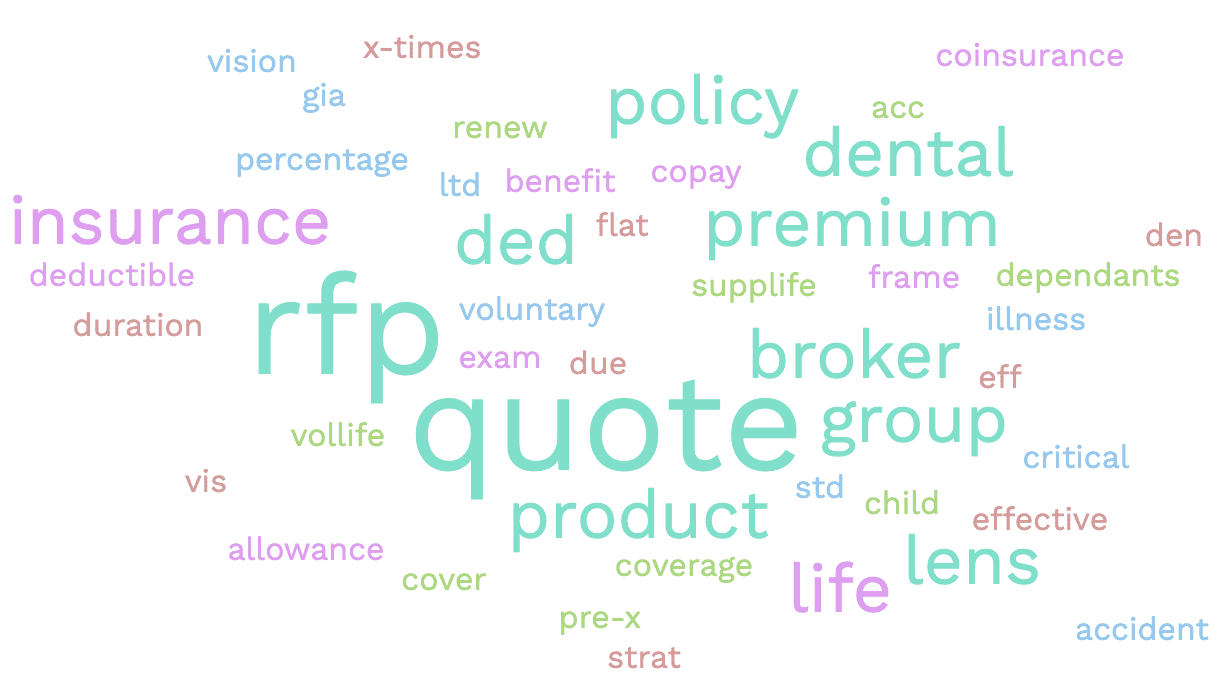
- Complex Data: Quotations from brokers widely vary in terminologies and can contain technical terms, acronyms, and jargon. The content can be highly subjective, necessitating contextual understanding and deep domain expertise. It is a challenge to train an AI model to capture these intricacies.
- Language Variant: Emails include a combination of dialects, language constructs, and grammar. It is quite common to see people using slang, emoticons, abbreviations, and colloquial language that are variant in nature. In the case of RFP emails, an additional level of complexity is variations in syntax, semantics, and terminology used by different brokers. These variants make it a challenge for AI models to interpret and extract the meaning from emails. The models must understand the nuances of the various industry specific language.
- Regulatory Compliance: Insurance companies must comply with strict regulations to ensure the security and privacy of customer data. AI models must comply with these regulations, including GDPR and HIPAA, and maintain data security and privacy. This requires effective planning and execution on how to handle, store, and destroy data. There must be auditable proof provided to customers to assure that their data (particularly PII data) is handled appropriately and is protected.
- Accuracy and Consistency: Accuracy and consistency in predictions are crucial for insurance data extraction. Incorrect data can result in errors in underwriting and pricing, which negatively impacts the organization’s profit parameters. AI models must extract data accurately and consistently across different data sources. If the models have lower confidence, then such extractions must be called out to possibly bring in a human-in-the-loop kind of construct.
- Data Volume: Insurance companies receive a large volume of emails daily. AI models must handle large amounts of data without compromising on the precision and timing requirements at the forefront of the pipeline design.
Using AI to automate the RFP quote intake process can help insurance companies reduce the time to respond to requests, giving them a competitive edge over those that process quotes manually. There are also potential benefits such as increased efficiency, monetary gains, and so on, without losing sight of the numerous challenges of using AI to extract unstructured data from emails in the insurance industry.
Ushur has overcome these obstacles and developed a data extraction framework for a Fortune 500 company. Using our intelligent data extraction capabilities and the Ushur Invisible App, our customer is now able to respond to incoming quote requests in 10 minutes rather than 5 to 6 days. Our AI pipeline can accurately identify and extract around 170+ entities from unstructured emails and provide highly structured information within a few minutes.
After conducting an extensive evaluation of various techniques, Ushur concluded that an ensemble of multiple methods was necessary to effectively extract the various entities from the email.
Ushur established a hierarchical relationship between the entities to accurately associate them with specific insurance concepts and devised mechanisms to narrow down the region of interest for each entity. An efficient modeling approach, which could capture these hierarchical relationships and select appropriate extractors for each entity was required to implement this. After careful consideration, Ushur determined that an ontology-guided method was the optimal choice.
This approach enables a structured and comprehensive framework to create the data extraction pipeline that ensures accurate and consistent results across large volumes of incoming emails from our customers. The approach is validated by accuracy rates exceeding 90% on a corpus of over 10k emails across a period of about 12 months. Ushur accomplished this by combining a novel ontology-guided extraction approach with an ensemble of NLP techniques.
Our approach
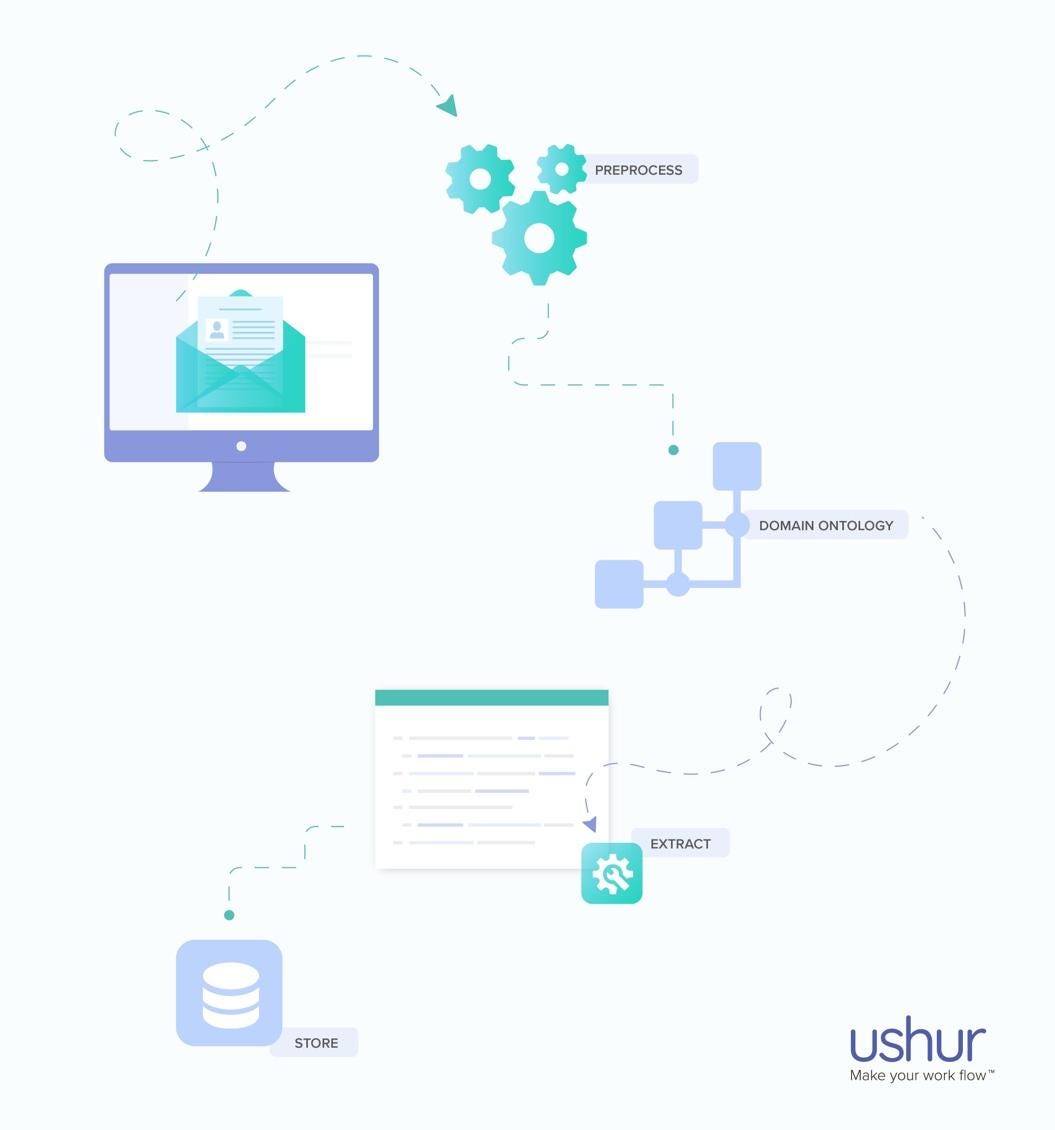





The steps involved are:
- Define Ontology: The ontology provides a framework for understanding email structure and content and can guide the information extraction process. For example, an ontology for the insurance industry might include concepts such as “broker,” “insurance policy quote,” and “group,” and relationships such as “group has an insurance policy” with properties such as “quote’s due date”, “broker’s name”, etc.
- Pre-processed Email: It is easy to work with pre-processed emails. This involves using NLP techniques such as tokenization, sentence segmentation, and part-of-speech tagging to identify and label relevant text components.
- Extract Data: The Ushur data extraction approach allows each node in the ontology to be associated with an extractor. These extractors could be simple regular expressions, NER-based (Named entity recognition), complex pointer networks, or an ensemble of extractors chained together.
- Store Data: Extracted data needs validation to ensure that it is accurate and complete. The extracted data is stored or presented in a structured format.
To conclude, an ontology-based approach provides a consistent framework for data extraction from unstructured content. When combined with the power of AI, this can assist businesses in automating and increasing the efficiency of their RFP intake process.


