Columnar data files are the dominant form used for exchanging information across industries like FMCG, Shipping, Finance, Insurance and others. The row-column format creates an understandable and recognized mechanism for sharing information which also happens to be easy-to-digest for digital processing. A lot of financial decisions and estimations are made off of information stored in rows and columns and colloquially the files are referred to as CSV’s (comma separated values). However, Microsoft Excel has quickly become the industry standard for visually processing CSV’s and it provides added user functionality like embedded tables, and the concept of “Sheets” where information can be logically partitioned.
There are many business conversations where data is exchanged via Excel/CSV files, and a classic example in the insurance industry is the dialogue between insurance brokers and insurance carriers. Here, CSV files are used to exchange information during the RFP (Request for Proposal) phase. The US has many insurance brokers. Brokers vary from individuals doing part-time work to small companies that employ a few people all the way to large brokers that employ hundreds of brokers.
When brokers meet prospective companies and need to quote them for their insurance needs, each broker communicates in their own styles and lexicon to represent the information they’ve gathered. For example, a simple column to represent “Date of Birth” can appear as “DOB”, “Birth date”, “Employee dob” and so on. Now, multiply that variability with about 100 columns of data for each customer and you understand why automating the process is so complex.
Automation and Efficiency are the primary goals of many carriers in the insurance industry in 2023. As more and more carriers automate portions of their backend and quote processes, discontinuity in data format and structure are exceedingly difficult to manage and thus need a lot of manual back-and-forth. It is estimated that in many cases, it may take anywhere from 1 to 5 days to clean and structure all information in formats necessary to correctly persist information in their System of Records (SOR’s).
This is where the Ushur Data Transformation Engine comes in and makes an immediate impact – adding automation to an intractable problem which was dominated by manual operations, and providing a high degree of efficiency by dramatically reducing the time taken to process the entire workflow.

In the RFP process, an insurance carrier typically receives hundreds of RFP requests per day. These RFP requests usually arrive in the form of emails being sent by the brokers to the sales executives. Among the numerous attachments, there is an excel file containing census information. This information generally includes: names of employees, birth dates, classes of employment, products required, premiums, specific clauses such as Cobra, eligibility for each member and so on.
This extraordinarily manual process invites automation to save on time and expense, and prevent overworked employees from introducing errors in data. Automating it, however, requires intimate knowledge of the process, a data standardization and cleaning routine, and user-friendly tools.
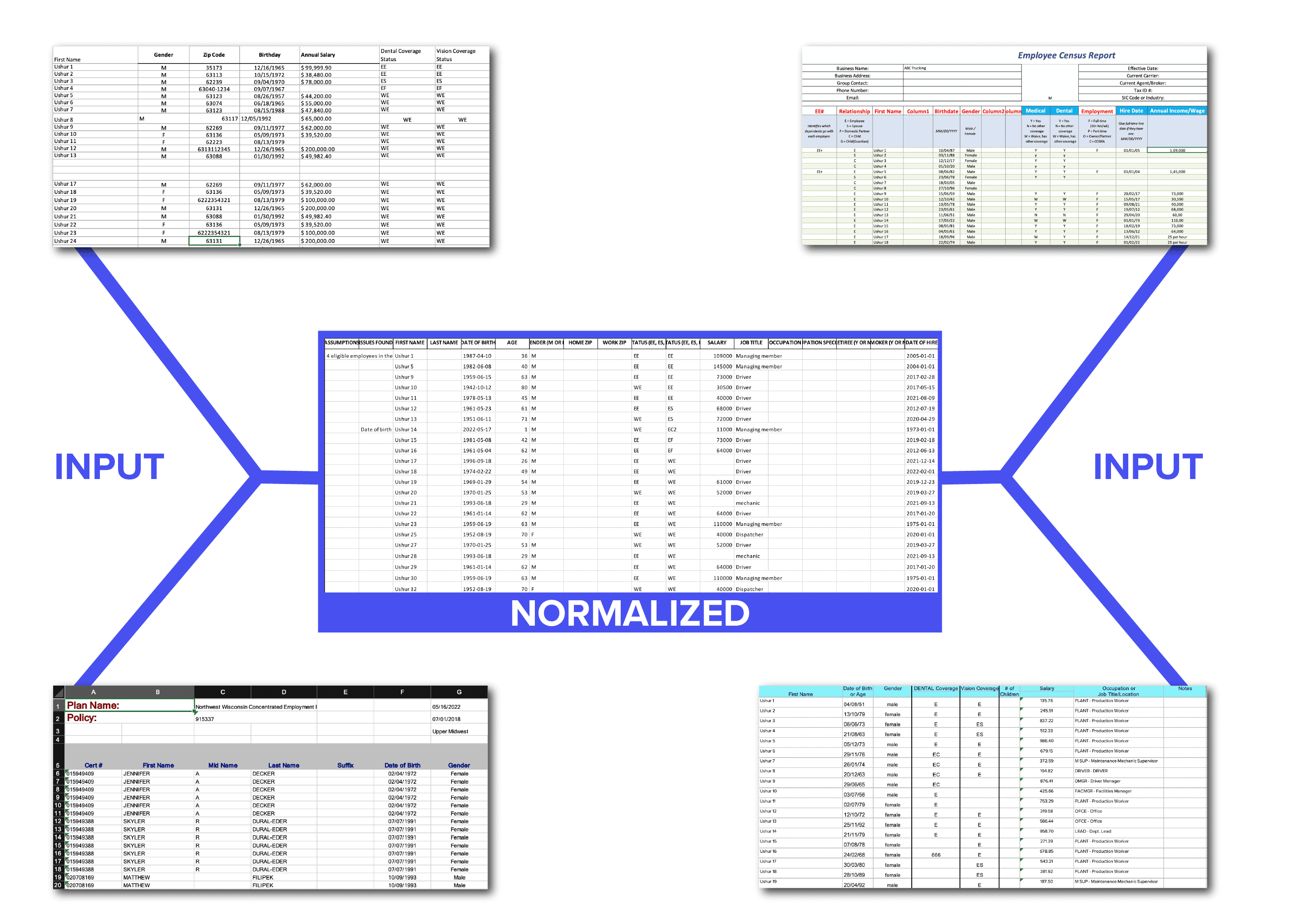
As Ushur went about solving this problem, we overcame many engineering challenges, some of which are listed below:
Ushur begins with table extraction. The data users want usually resides in tables within these excel files. Surrounding the tables are huge chunks of irrelevant data such as legends, demography info, huge headers, titles and other noise. The extraneous noise affects the performance of downstream tasks such as classification and transformation. The Ushur novel table extraction algorithm helps us to effectively customize table extraction for multiple use-cases. We use a combination of NLP and Vision Techniques to solve this problem.
The next step is column classification. Ushur recognises different column headers and normalizes them into CRM accepted headers. Since these excel files are sent by multiple brokers from around the world, the variation in representation of the data is immense. Ushur’s domain specific models help to cater to use-cases per domain.
The final steps are transformation and validation. A lot of transformations and validations are required to be performed on these normalized input tables. This ensures data consistency and easy feed into the customer’s system of record. Since, this is a highly customizable problem depending on various use-cases, it’s imperative that we enable citizen developers to perform these operations at their convenience. We enable this by the mechanism of “rules”. We have created our own rule language that end users can use to write their rules.
Once we have executed the above steps, we now have a clean, normalized and consistent excel file. We send back this asset as an excel file or as a JSON to be fed into the customer’s CRM.
Ushur’s columnar data transformation engine is a part of the patented Ushur Document Intelligence Services Architecture (DISA) and deployed within Ushur Intelligent Document Automation™ (IDA). DISA applications have led to significant improvements in business metrics for our customers – in one case, one of Ushur’s clients was able to reduce manual labor from 30-36 hours to about 3 minutes, and see many examples where there was no human intervention of any kind, freeing up agents to focus on high-touch, more meaningful interactions, rather than back office tasks. Best of all, the ability to create new rules very quickly via the Ushur no-code flowbuilder enables Ushur to provide ROI to customers in days.



